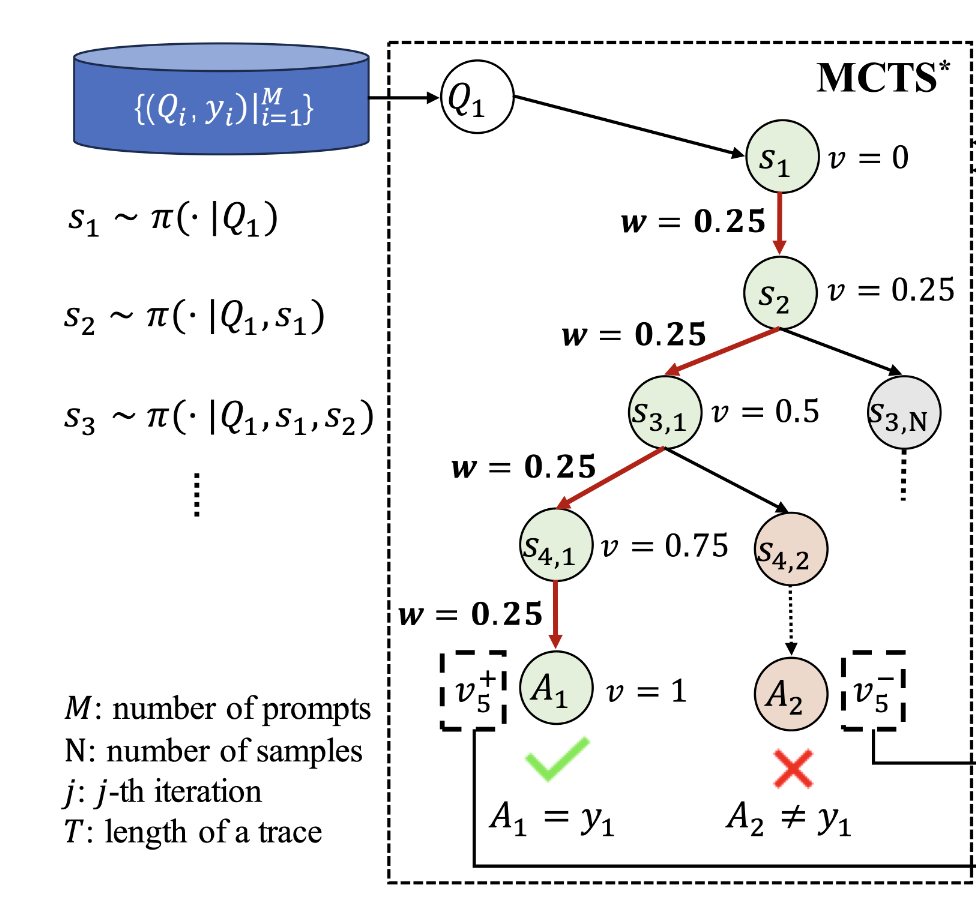
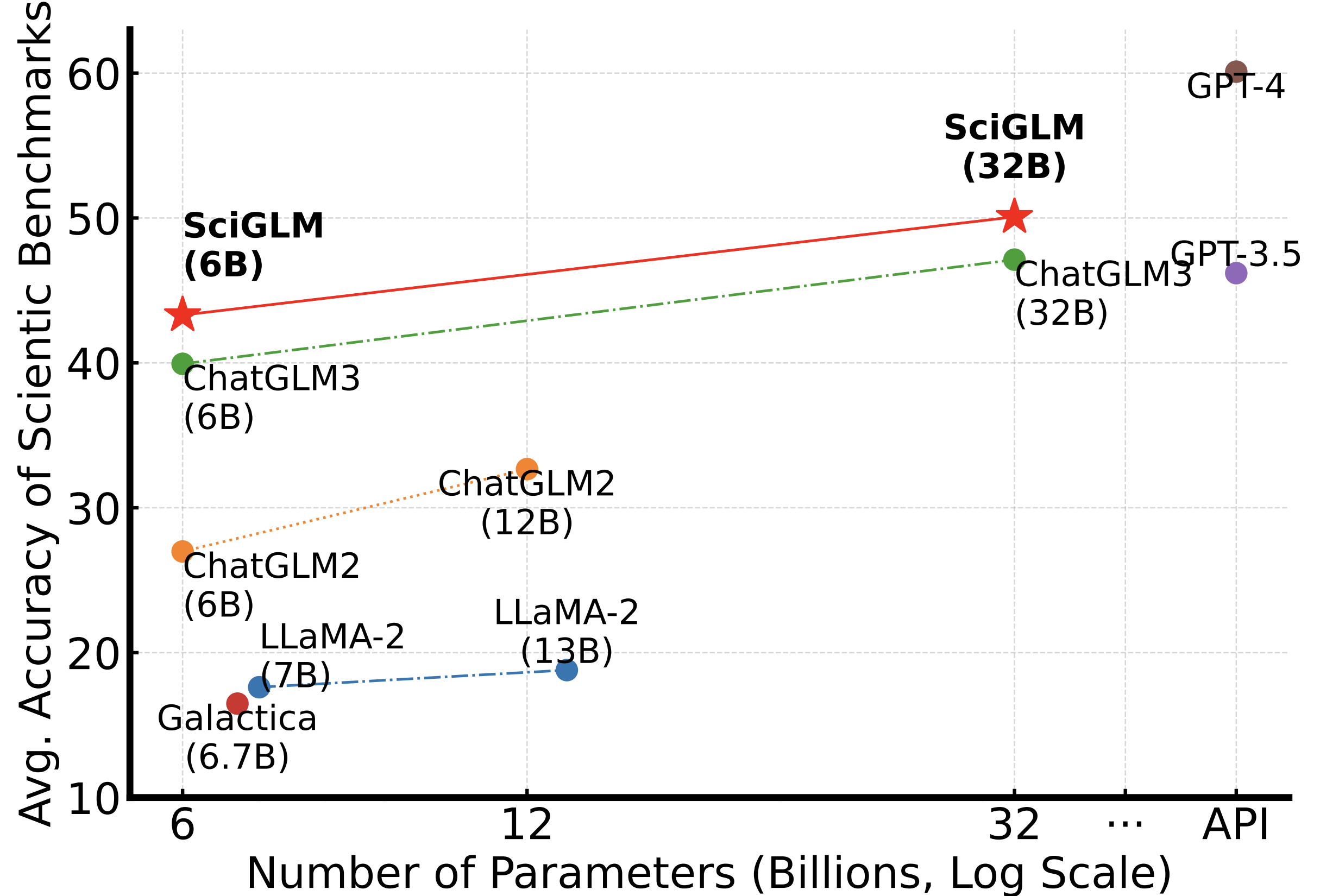
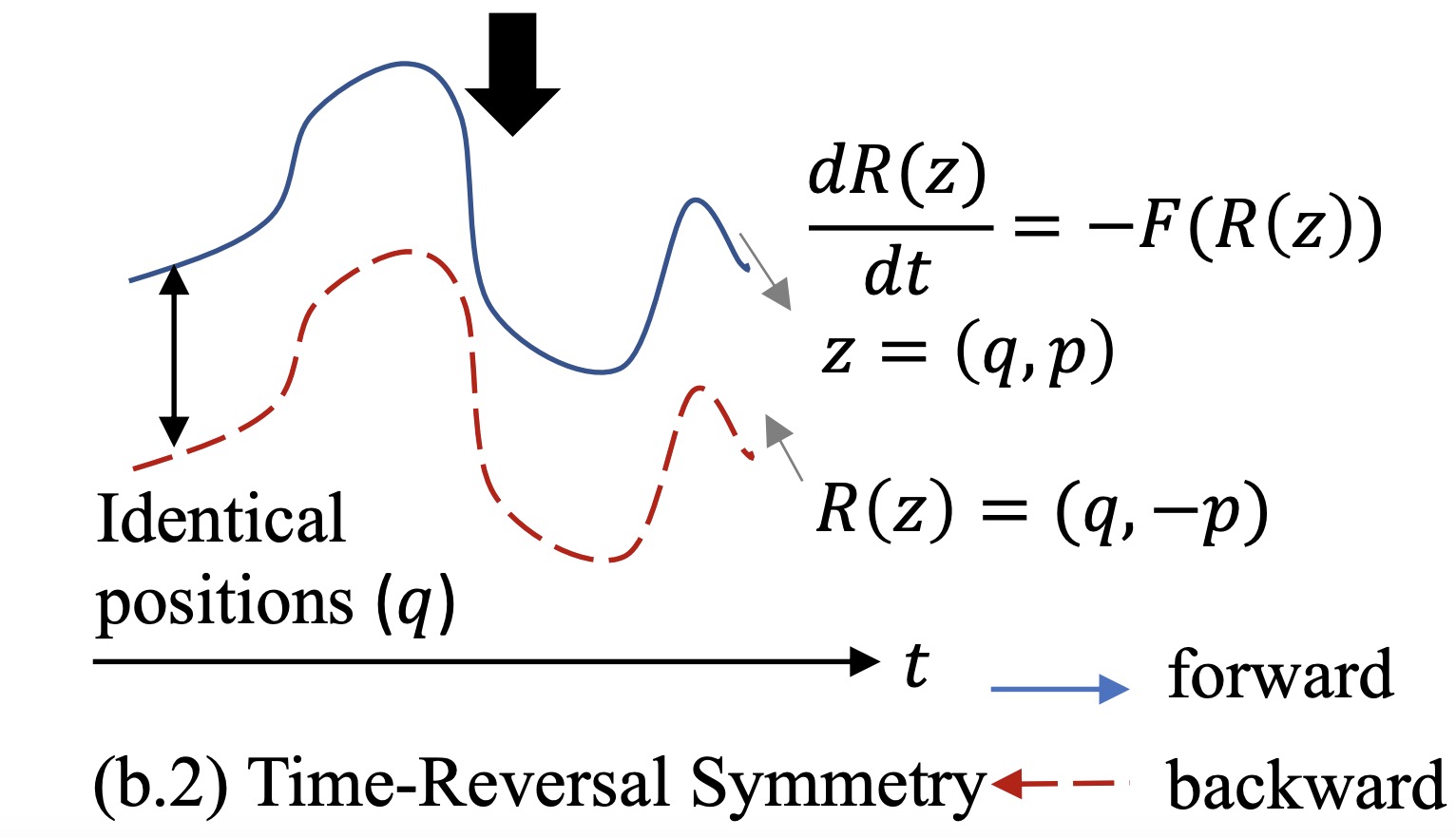
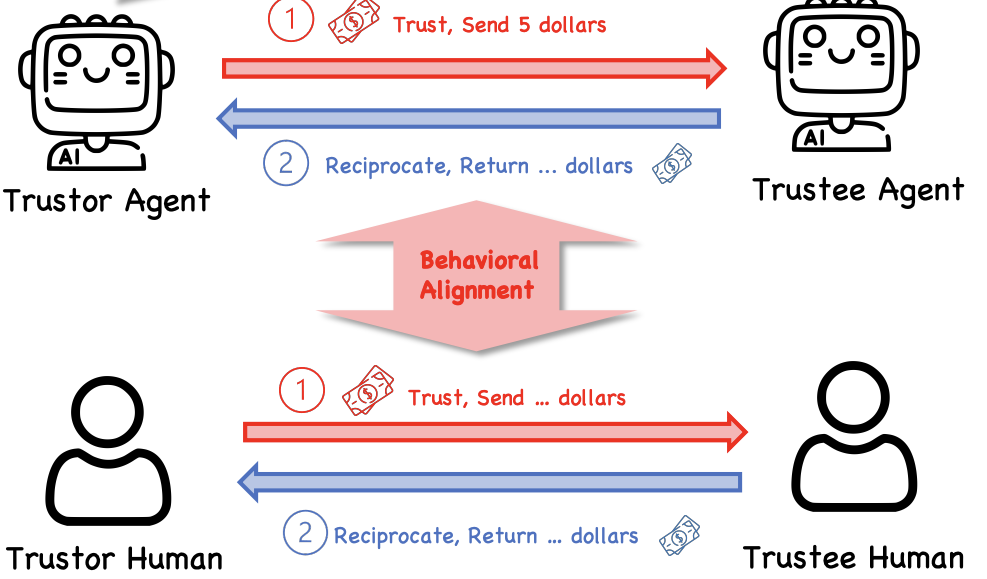
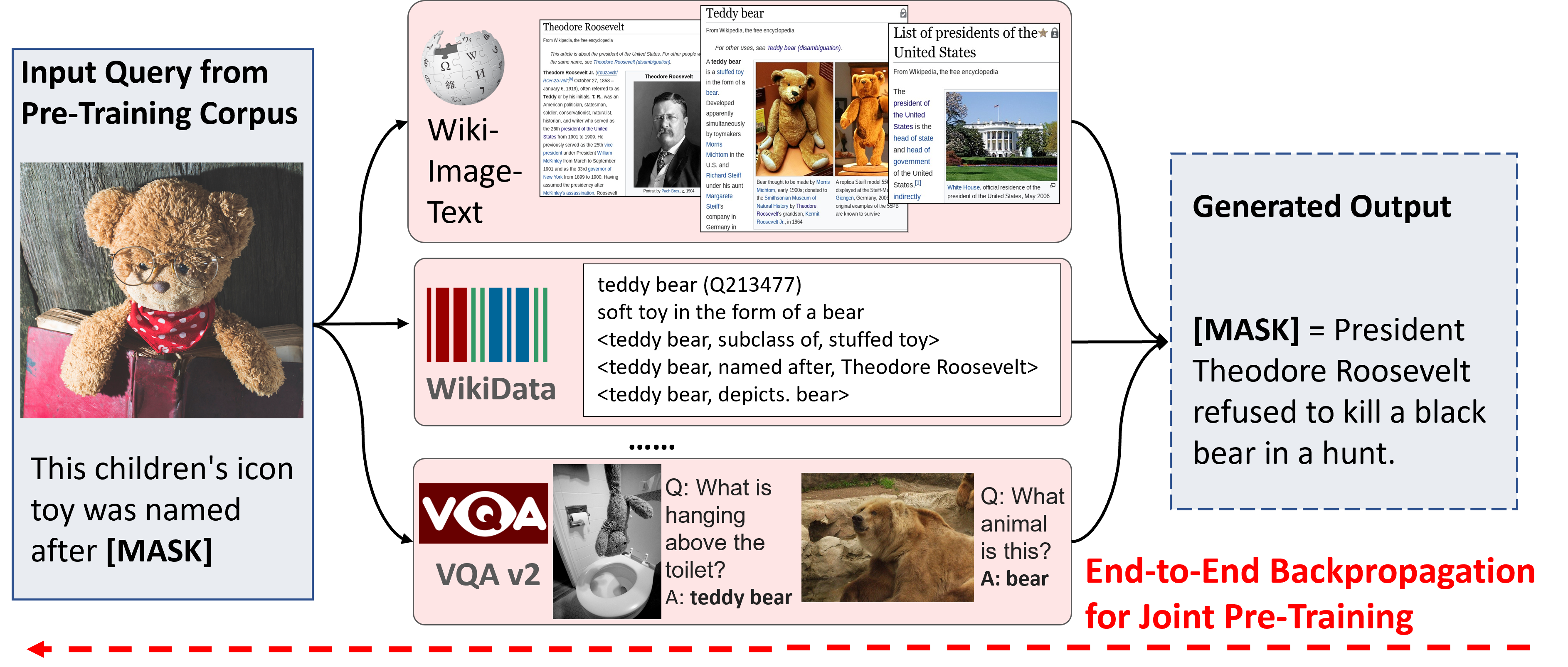
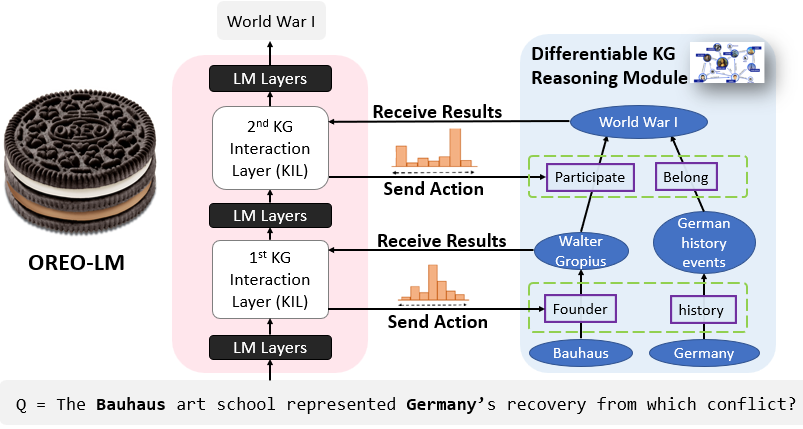
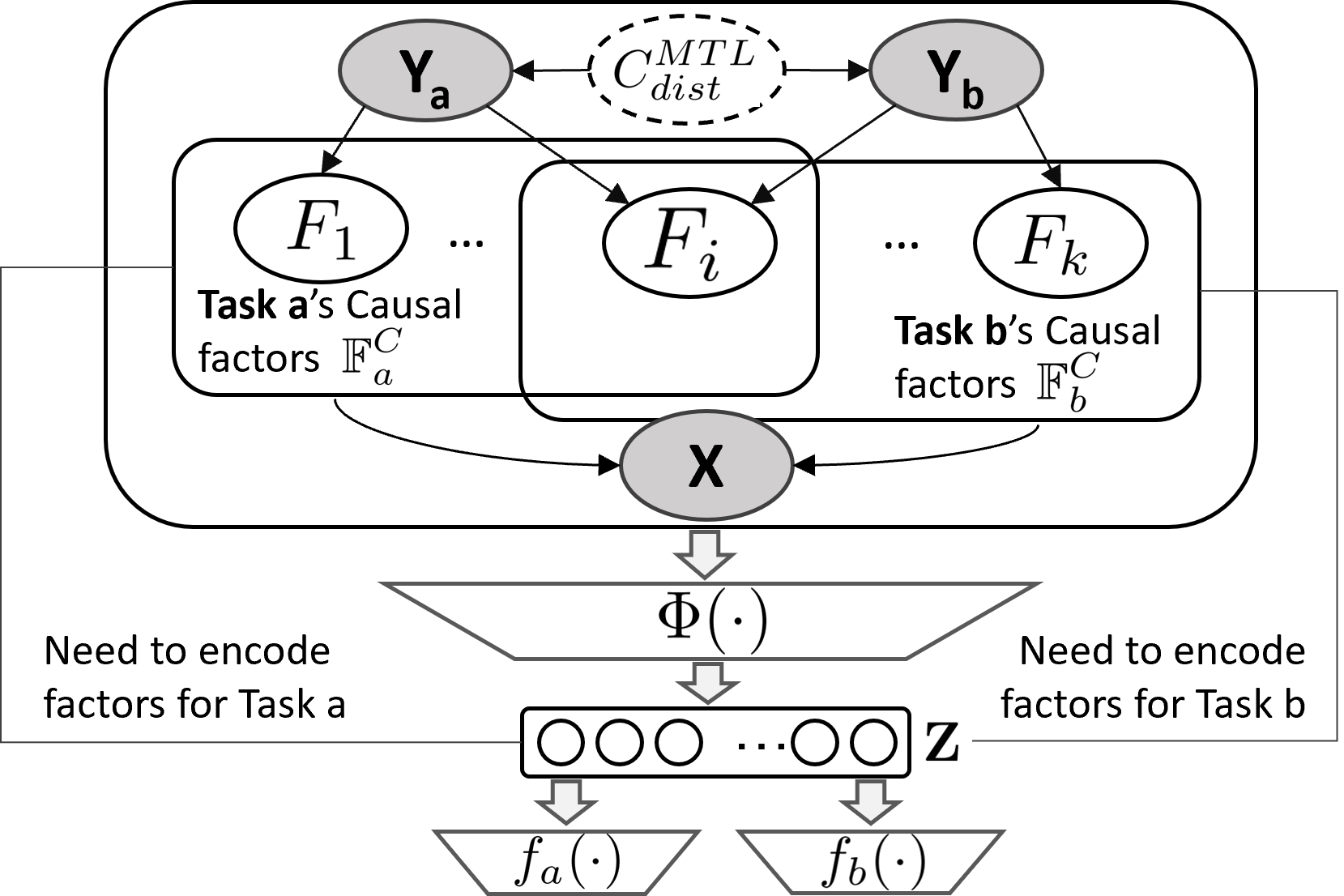
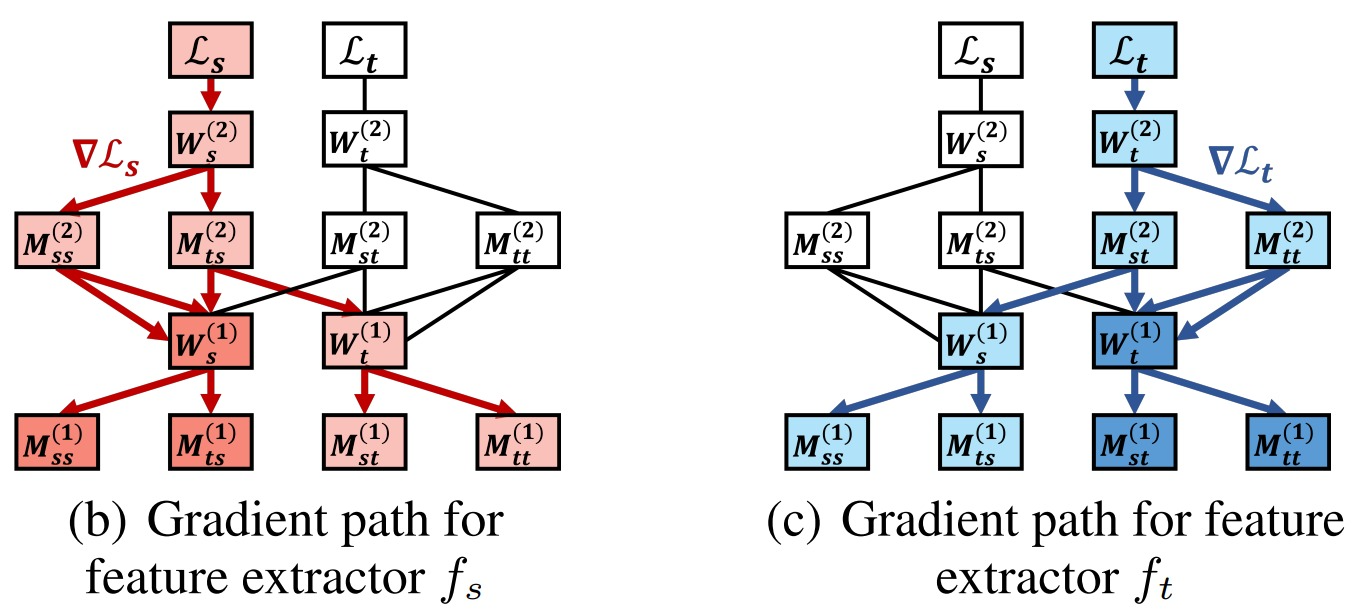
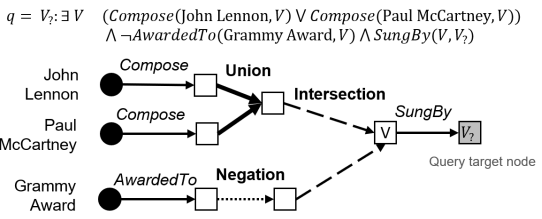
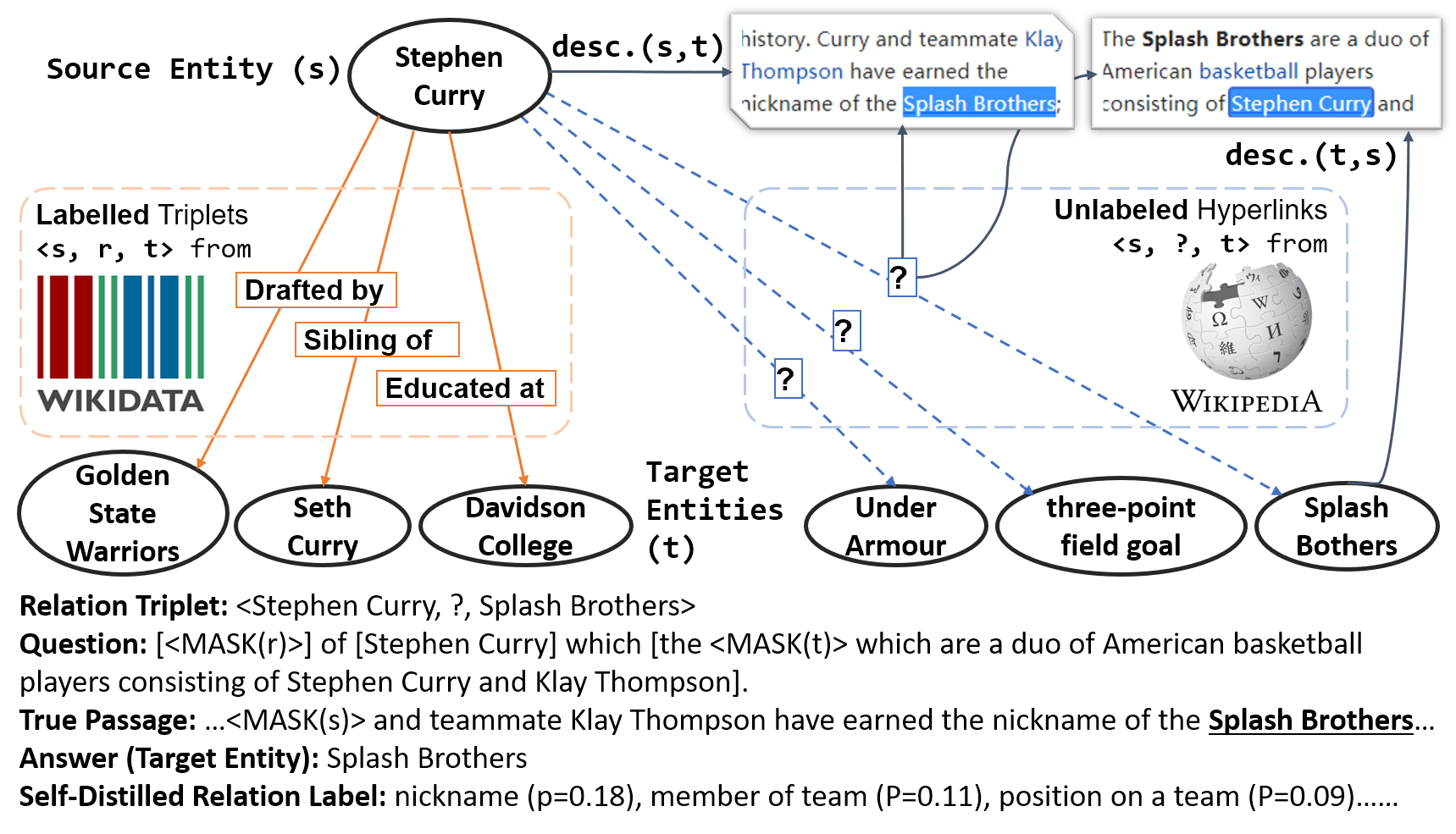
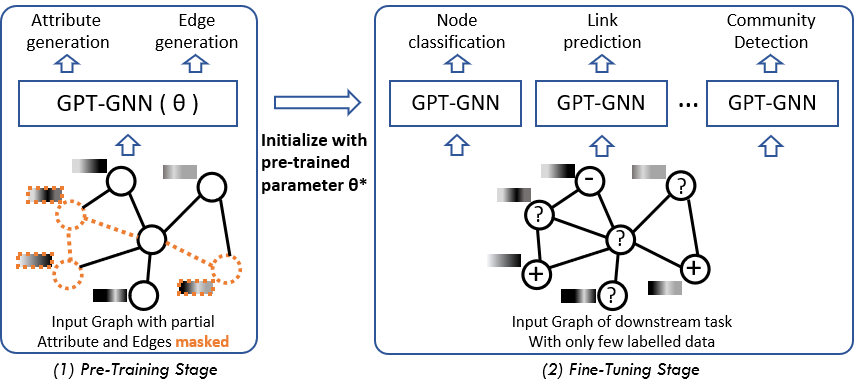
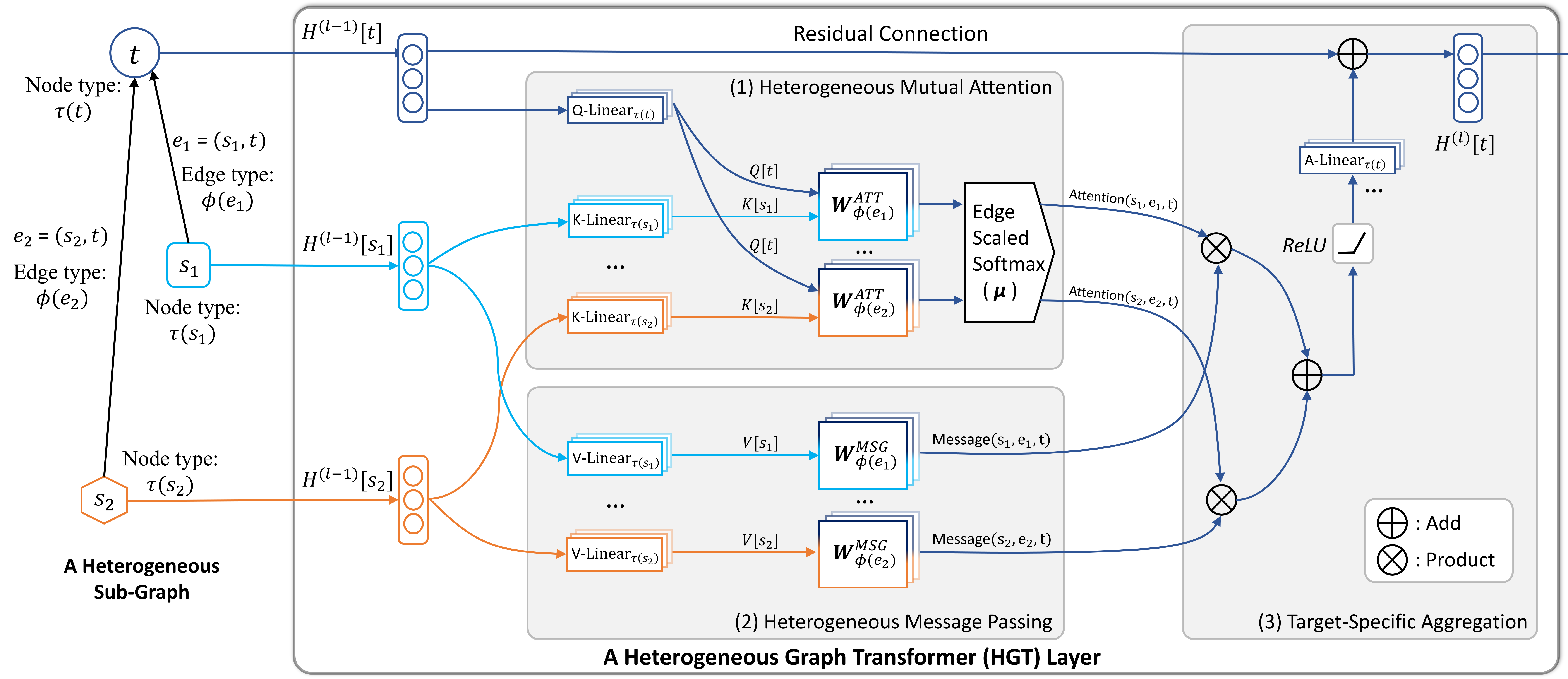
About
I was working at xAI, reinforcing Large Language Models (e.g. Grok Code Fast 1, Grok 3-mini Reasoning, Grok 3 and Grok 2) to solve real-world problems.
I finished Postdoc at Caltech CMS hosted by Prof. Yisong Yue, during which I was also a visiting researcher at Google DeepMind. I received CS PhD degree at UCLA, where I had the fortune to be advised by Prof. Yizhou Sun and Prof. Kai-Wei Chang. I received my CS bachelor degree at Peking University, advised by Prof. Xuanzhe Liu. My research is generously supported by Amazon PhD Fellowship and Baidu Scholarship. My PhD thesis on Neural-Symbolic AI won the ACM KDD 2024 Dissertation Award - Runner Up .
Education
-
Ph.D. of Computer Science
Sept. 2018 -- May 2023University of Calofornia, Los Angeles
Thesis: Make Knowledge Computable: Towards Differentiable Neural-Symbolic AI
-
B.Sc. of Computer Science
Sept. 2014 -- Jun. 2018Peking University
Academic Awards
- ACM SIGKDD 2024 Dissertation Award - Runner Up
- Best Paper Award, NeurIPS 2023 Workshop (DL + Differential Equation)
- Best Paper Award, SoCal NLP Symposium 2022
- Best Student Paper Award, KDD 2020 Workshop (DL on Graphs)
- Best Full Paper Award, WWW 2019
Services
- Research Track Workflow Co-Chair: SIGKDD 2023
- Area Chair of ICLR, NeurIPS, ACL 2025, ICLR, ICML 2026
- NeurIPS 2022 Top Reviewer Award
- Workshop Co-Organizer of Tool-VLM @ CVPR'24 and SSL @ WWW'21